
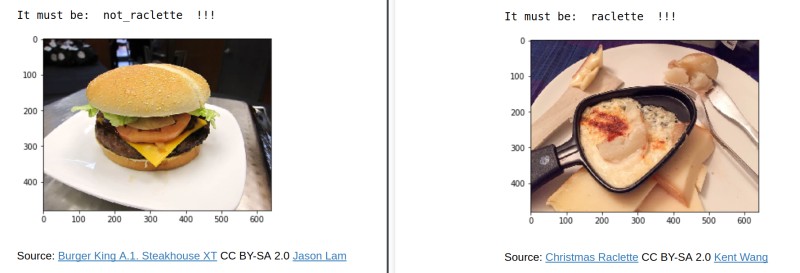
From Lausanne's Applied Machine Learning Days to Basel's Open Food Data Hackdays: this is a project about exploring the classification of images of food. Machine learning techniques allow us to automatically decide whether a given photograph is Raclette, or is Not Raclette (this being a popular Swiss dish, y'all).
A Jupyter notebook with example Python code and annotations can be viewed here, downloaded from gist.github.com, and run again on a training set of images.
Training data could be collected from Wikimedia Commons, Flickr, DuckDuckGo, extracted from a machine learning dataset like ImageNet (* academic credentials required for access) or Multimedia Commons, or even collected on crowdsourcing platforms and social media.
During the Hackdays, we learned about the Food101 dataset created by researchers at the ETH in Zürich. This is apparently often cited[citation needed] in machine learning papers. It could prove useful for this challenge, so we have a local copy available in Basel (please avoid clogging up our network and get it on a USB stick) for anyone who wants to give it a try. Note that this dataset is provided for scientific fair use only, and any other uses need to be negotiated with Foodspotting.
Developer notes
An easy way to run our demo code is Anaconda, with this command to install dependencies:
conda create -n pytorch pytorch matplotlib PIL
Install the latest version of torchvision from GitHub using pip:
pip install https://github.com/pytorch/vision/archive/master.zip
You can then add images to the data folder using labels for your classifier, as instructed in the notebook. If you prefer a plain Python script version, download classification.py. Introductory material to the PyTorch framework can be found at PyTorch Tutorials and ZeroToAll (YouTube). You are, of course, welcome to use another framework or approach to respond to this challenge.
All code shared here is open source under the MIT License.
With thanks to Open Food Hackdays 2018 Lausanne participant @syllogismos for mentorship and to @zouying for the bootstrap. Chat about this challenge and share data with us through the contact link above.
Next steps
- collect open data
- optimise model layers
- save the intermediary model
- build it into a mobile app
- ...
- PROFIT!
Connect to our community on
![]() Mattermost
| Twitter
| Facebook
Mattermost
| Twitter
| Facebook
 The contents of this website, unless otherwise stated, are licensed under a Creative Commons Attribution 4.0 International License.
The contents of this website, unless otherwise stated, are licensed under a Creative Commons Attribution 4.0 International License.
Open Food Hackdays Basel
Next project