
Report
💡 Active projects and challenges as of 27.06.2026 10:20.
Hide text CSV Data Package Print
Projektanalyse Online
Versuch die bestehende Projektanalyse vom Excel-File in ein Nutzer*innen freundliches Web Format zu bringen
Projektanalyse Online
Die Auswirkungen eines Projekts auf Umwelt, Wirtschaft und Gesellschaft mithilfe der vorhanden Excel Sheets zu erfassen ist ein langwieriger und unübersichtlicher Prozess. Mit der Projektanalyse Online versuche ich Abhilfe zu schaffen.
Die Lösung Die Nutzer*innen werden schrittweise durch den Projektanalyse Prozess gelotst. Ein intuitives und ansprechendes UI soll dies so angenehm wie möglich machen. Im ersten Schritt werden den Nutzer*innen Handlungsgrundsätze präsentiert. Die Idee ist, dass sie diese auf den nächsten Schritten im Hinterkopf behalten. Anhand von je 6 Fragen werden nun die Auswirkungen des Projekts auf die Wirtschaft, Umwelt und Gesellschaft erfasst. Ein Balkendiagramm zeigt die Auswirkungen. Wird eine Analyse vorerst abgeschlossen, erscheint sie im Suchfenster. Durch ein Anklicken öffnet sich das Kanban Board. Die Idee dabei ist, dass Themenpunkte auch zu einem späteren Zeitpunkt im Projekt nochmals neu beurteilt werden können. Um diese Änderungen nachvollziehbar zu machen, ist aber eine Begründung nötig. Der Verlauf von Neubeurteilungen per Themenschwerpunkt kann durch anklicken auf das Kanban Board eingesehen werden.
Learnings Während dem Hack habe mich intensiv mit UI Design und Entwicklung auseinandergesetzt. Ich nutzte Tailwind.css und lernte viele neue Utility Classes kennen.
Technologie Das Frontend ist mit Blazor und Tailwind programmiert, das Backend mit ASP.NET Core. Es wird auf Azure gehosted.
Video Link
GitHub Repo Link
Bilder Landing Screen mit Suchfenster zum browsen von bestehenden Analysen
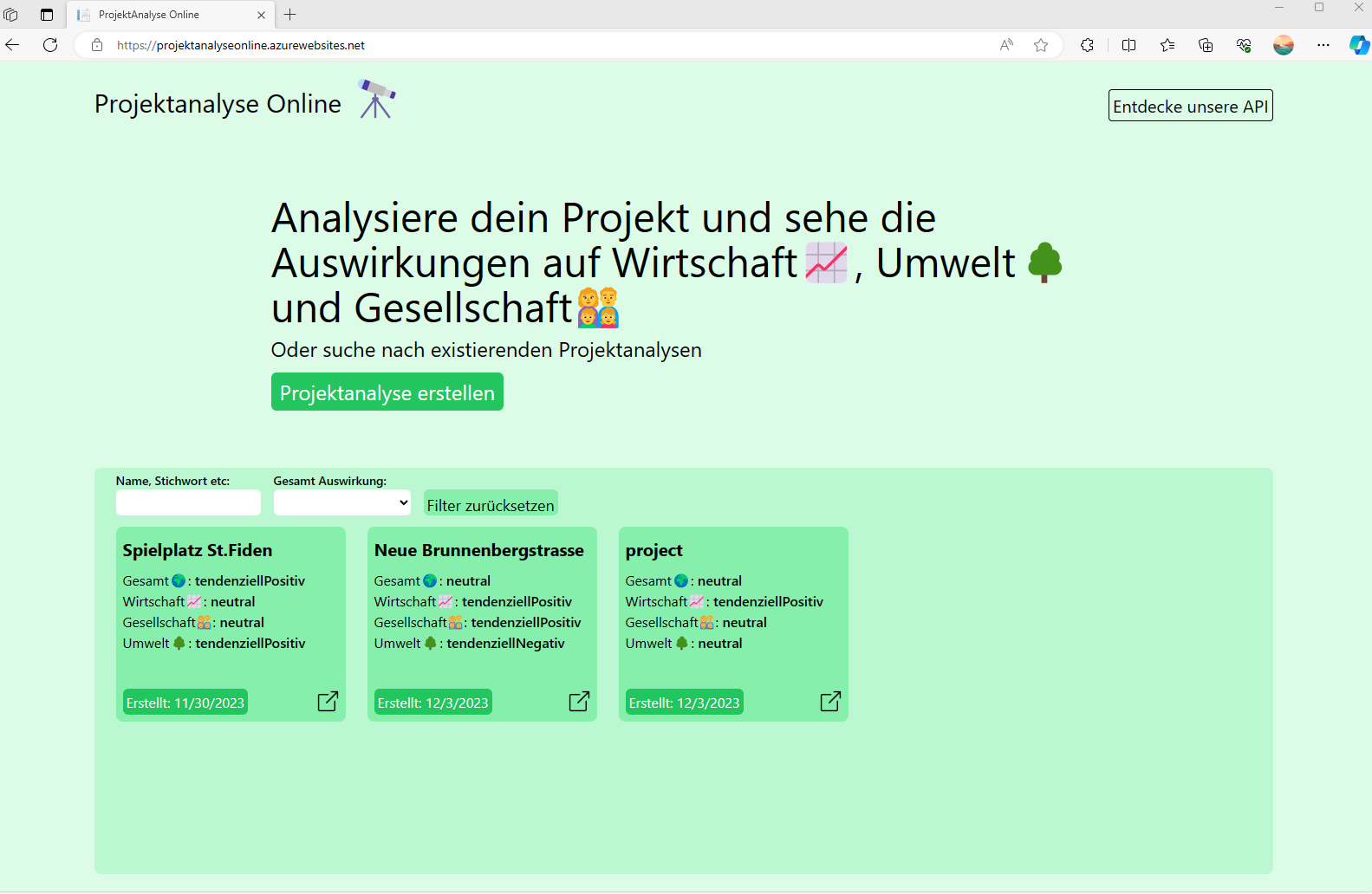
Ausschnitt aus Analyse Prozess: Die Balken am oberen Ende der Seite zeigen die Position im Analyse Prozess. Die Beantwortung der Fragen funktioniert durch die Slider.
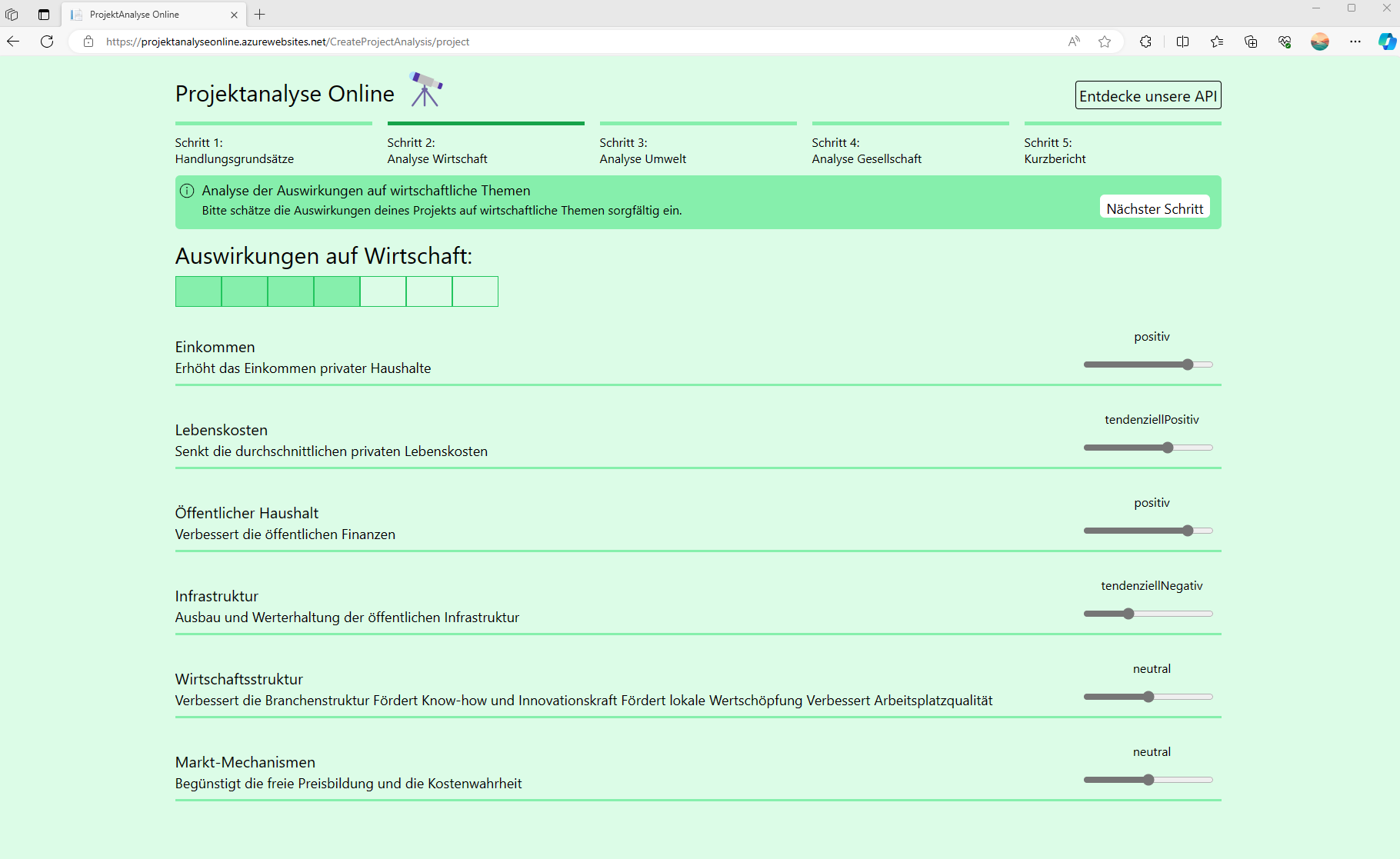
Kanban Board mit Übersicht über die Einteilung der jeweiligen Themenschwerpunkte. Die Einteilung der Themenschwerpunkte basiert auf der Beantwortung der Fragen bei der Projektanalyse. Per Drag&Drop können Updates vorgenommen werden. Die Eingabe eines Grundes für die Beurteilung hilft späteren Besuchern beim besseren Verständnis.
GreenLight
GreenLight vereinfacht mittels KI und einer einfachen und übersichtlichen Website die Projektanalyse bezüglich Nachhaltigkeit von Projekten.
PDF Sustainibility Analyzer for Projects
Team Members
- Nathalie Kern
- Maria Näf
- Sophie Maier
Overview
To improve the projectmanagement method regarding sustainability, the projectteam created a PDF analyzer with a Chat GPT API.
Prerequisites
Following must be installed on your system:
- Python
- Git
Setup
Here's how you can set up your development environment:
# Clone the repository
git clone https://github.com/sophiemaier/Open-Data-Hack-2023
# Navigate to the project directory
cd Open-Data-Hack-2023
# Create a Python virtual environment in the 'venv' directory
py -m venv venv
# Activate the virtual environment (use the correct command for your operating system)
venv\Scripts\activate # For Windows in Git Bash
# or
source venv/bin/activate # For Unix or Linux systems
# Install the project dependencies from 'requirements.txt'
pip install -r requirements.txt
# Create a API key from chat gpt on their website and replace "YOUR KEY" with your key. After that, create a '.env' file in the 'OpenDataHack2023' directory with the following content
echo OPENAI_API_KEY="YOUR KEY" >> .env
# Run the local development server or script (specify the script if it's not 'app.py')
streamlit run app.py
Megatron on ICE
Auto-fetch, clean JSON to NOSQL, LLAMA-indexed access to real-time building data via NLP prompts, ensuring accuracy.
Auf der sitios Webseite werden umfassende Wnformationen zum Zutritt zu öffentlichen Gebäuden für menschen mit Einschränkung in der Mobilität bereitgestellt. Aufgrund der grossen Menge an Informationen ist es für die Benutzer aber oft schwierig, ihren Besuch zu planen. Unsere Lösung sammelt die vorhandenen Daten, bereinigt diese und speichert diese in einer NOSQL-Datenbank ab. Anschliessend können die Benutzer Fragen zu ihrem Besuch im jeweiligen Gebäude mittels Chatbot stellen und bekommen ihre Antwort ebenfalls als kurzen ganzen Satz. Dies erleichtert die Planung eines Besuchs und macht die Webseite von sitios attraktiver und einfacher zu nutzen.
The video pitch is available at (swiss german): OpenDataHackSG_2023/video_pitch/MEGATRON_ON_ICE_video_pitch.mp4 at christoph · clandolt/OpenDataHackSG_2023 (github.com)
The project description is available at: clandolt/OpenDataHackSG_2023 (github.com)
Sitios Accessibility Information System
Überblick
Das Sitios Accessibility Information System wurde entwickelt, um detaillierte Informationen über die Zugänglichkeit von Gebäuden zu liefern. Die Herausforderung besteht darin, die Vielfalt der Bedürfnisse verschiedener Menschen, insbesondere solcher mit besonderen Anforderungen, zu berücksichtigen. Dieses README erklärt den Lösungsansatz und wie die Anwendung verwendet werden kann.
Aufgabenstellung
Die Aufgabenstellung besteht darin, genaue und detaillierte Informationen über die Zugänglichkeit von Gebäuden zu erfassen und für die Nutzer leicht zugänglich zu machen. Unterschiedliche Arten von Rollstühlen und individuelle Bedürfnisse machen es notwendig, dass die Informationen äußerst präzise und vielseitig sind. Das aktuelle Format der Informationen auf der Sitios-Website ist jedoch aufgrund der Menge an informationen teilweise unübersichtlich und schwer zu navigieren.
Lösungsansatz
Um die Herausforderungen der aktuellen Informationsdarstellung zu bewältigen, wurde der folgende Lösungsansatz entwickelt:
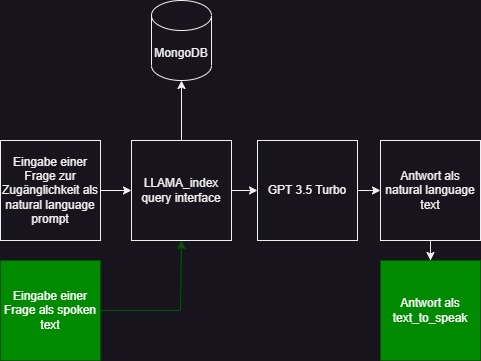
1. Auto-fetch und Clean JSON to NOSQL
Die Lösung implementiert einen Webcrawler zum automatischen Herunterlaen der JSON-Dateien über die öffentlichen Gebäude. Diese Daten werden dann bereinigt, in einem klaren JSON-Format organisiert und in einer NOSQL-Datenbank gespeichert. Dieser Prozess gewährleistet, dass die Informationen aktuell und strukturiert sind.

2. LLAMA-Indexed Zugriff auf Echtzeit-Gebäudedaten
Um die Zugänglichkeit der Informationen zu verbessern, verwendet die Lösung ein LLAMA-Indexierungssystem. Dieses System ermöglicht einen schnellen und effizienten Zugriff auf relevante Daten. Die LLAMA-Indexierung ist wichtig, damit das Modell die Antwort anhand der Daten übers Gebäude beantwortet und nicht mittels generativer AI irgendwelche informationen erfindet. Zudem ermöglicht das LLAMA-Indexierungssystem mit der query-Funktion gezielt nach spezifischen Informationen zu suchen.
3. NLP-gesteuerte Abfragen für Genauigkeit
Die Lösung integriert ein GPT 3.5-Turmo Natural Language Processing (NLP)-Modell, um den Nutzern die Möglichkeit zu geben, präzise Abfragen zur Zugänglichkeit von Gebäuden durchzuführen. Dies trägt dazu bei, dass die Informationen genau und relevant sind. Nutzer können Fragen in natürlicher Sprache in unterschiedlichen Sprachen stellen, und das System wird die passenden Informationen liefern.
Anwendung
Die Anwendung ist aktuell nur lokal verfügbar kann aber über dieses Github repo einfach auf einem Webserver integriert werden.
Mitwirkende
- Christoph Landolt
- Noah Lüchinger
- Ruwen Frick
Parcaster
Analysis and ML based prediction of free parking spaces in St. Gallen.
ParCaster
Ausgangslage
Die Suche nach einem Parkplatz hat viele negative Auswirkungen, wie z. B. Zeit-, Treibstoff- und Emissionsverschwendung, überhöhte Parkgebühren usw. Um die Parkplatzsuche zu erleichtern, ist das Ziel dieses Projekts durch die Anwendung von maschinellem Lernen die Verfügbarkeit von Parkplätzen in der Stadt St. Gallen zur geschätzten Ankunftszeit der Nutzer vorherzusagen. Der Nutzer erhält eine personalisierte Parkplatzempfehlung.
Beschreibung ParCaster
ParCaster ist eine künstliche Intelligenz, welche freie Parkplätze in der Stadt St. Gallen vorhersagt. Das zugrundeliegende Modell erstellt aufgrund von Inputs wie z.B. der Wetterprognose, von Feiertagen und Veranstaltungen oder auch Schulferien entsprechende Prognosen. Der Nutzer kann auf der Website die voraussichtliche Parkzeit eingeben, worauf ParCaster die Anzahl freie Parkplätze je Parkgarage in der Stadt St. Gallen vorhersagt. Der Nutzer spart Zeit und Geld.
Website ParCaster
Vorgehen und Implementierung
Die Entwicklung des ParCasters kann in die Schritte Data-preprocessing, Modellentwicklung und Erstellung des Web-Services unterteilt werden. Die einzelnen Schritte werden nachfolgend kurz erläutert:
Data und Datapreprocessing
Die Daten, welche dem entwickelten Modell zugrunde liegen, werden vom Open-Data-Portal der Stadt St. Gallen (https://daten.stadt.sg.ch/explore/dataset/freie-parkplatze-in-der-stadt-stgallen-pls/table/?disjunctive.phid&disjunctive.phname) öffentlich zur Verfügung gestellt. In den Daten wird dargestellt, wie viele Parkplätze zu einem bestimmten Zeitpunkt in den Parkgaragen der Stadt St. Gallen frei sind. Die zur Verfügung stehenden Daten sind aus dem Zeitraum zwischen Oktober 2019 und November 2023. Bevor die Daten für die Kalibrierung des Modells verwendet werden, werden sie bereinigt. U.a. werden Ausreisser entfernt. Zudem werden die Daten normalisiert und neue Features generiert.
Modellentwicklung
Mit den vorbereiteten Daten wird ein LSTM (https://de.wikipedia.org/wiki/Long_short-term_memory) in Python trainiert. Dabei werden unterschiedliche Werte für diverse Parameter (u.a. Anzahl Layer, Batch-Size, Optimizer) ausprobiert. Als Loss-Function wird der MSE verwendet. Die Resultate werden mit Weigths & Bias getrackt. Die Ergebnisse können auf der folgenden Homepage eingesehen werden: https://wandb.ai/parcaster/pp-sg-lstm/sweeps/zx34brsw
Das entsprechende Jupyter Notebook ist unter folgenden Link zu finden: https://github.com/parcaster/parcaster/blob/master/model/W%26B_PPSG_LSTM.ipynb
Die untenstehenden Grafiken zeigen beispielhaft den Vergleich der Vorhersage mit den effektiven Werten nach dem Training. Dabei sind die Vorhersagen für Testdaten gemacht worden, welche das Modell während des Trainings nicht gesehen hat:
Vorhersage vs. effektive Werte für den 01-03-2023 00:11 Uhr

Vorhersage vs. effektive Werte für den 01-03-2023 02:27 Uhr

Erstellung Web-Service
Das trainierte Modell wird über eine API auf Heroku deployed. Damit der Nutzer für den benötigten Zeitpunkt eine Prognose zu den freien Parkplätzen abfragen kann, wird ihm ein User Interface zur Verfügung gestellt. Das Userinterface wird mit Github Pages erstellt.
Nächste Schritte
- Verbesserung des Modells (LSTM)
- Weitere Modelle testen (statistische Modelle, Transformer)
- Preprocessing der Daten verfeinern (z.B. weitere Features entwickeln)
Mögliche Weiterentwicklungen
- Vorteile der einzelnen Parkmöglichkeiten in User Interface darstellen (z.B. überdacht vs. nicht-überdacht)
- Distanz zum Zielort in Vorschlag einarbeiten
- Parkplatz über User Interface vorreservieren für gewünschten Zeitpunkt
Rocero: Auswertung des Füllverhaltens der Glassammelstellen
Wir haben Korrelation zwischen Bevölkerung und Füllverhalten analysiert, sowie eine zeitliche Vorhersage der Füllhöhe pro Sensor errechnet.
Open Data Hack SG 2023: Füllverhalten von Glas-Sammelstellen
-
Untersuchung der Fülldaten
-
Bereinigung der Fülldaten
- Ausreisser entfernen
- Glätten
-
Splitten der Daten in Perioden zwischen Entleerungen
-
Trainieren eines linearen Modells mit linearer Regression
-
Graphen von den Trainieren Modellen
{kind=link}
{kind=link}
{kind=link}
Aufbau des Repos
- Sensordaten und lineares Modell
src/prepare_and_split_data.py: Script um Sensordaten zu Bereinigensrc/prepare_and_split_data.ipynb: Experimenteller Code um Sensordaten bereinigensrc/calculate_slope_per_station.py/.ipynb: Füllgeschwindigkeiten von bereinigten Sensordaten berechnen.src/calc_prediction_accuracy.py: Berechnen des Standard Errors mit Testdaten.
- Zusammenhang von Füllgeschwindigkeit und Bevölkerungsdichte
src/get_population_per_collection_point.py: Zuweisen von Quartier/Bevölkerung und Sammelstellesrc/calculate_slope_with_population.py: Untersuchung von Zusammenhang
Resultate
Diagramme und Grafiken in img/ Ordner.
Füllgeschwindigkeiten und weitere statistische Werte in results/*_slopes.csv.
Infos
- So, 9:00: Submission
- Dribdat Project https://hack.opendata.ch/event/66
- 3min Pitch Video
Team
- Dominik Gschwind, @N3xed
- Cedric Christen, @cedi4155476
- Roman Weiss, @romanweiss123
- Roméo Bornand
OST SML
Routenplaner für die nächste Woche
Wir nutzten ein Long short-term memory neuronales Netztwerk um alle Routen der nächsten Woche in Google Maps zu planen
Für den Google Drive Link muss man den Link eventuell in einem separaten Fenster öffnen.
Open Data Hack 2023
Initial Goal 🎯
Use an LSTM AI model to predict the fill levels of recycling stations in St. Gallen and create a pathfinding algorithm that finds the ideal routes for city employees, for the next work week.
Components 🧩
- AI model that predicts future fill levels based on historic data
- Pathfinding algorithm that finds the optimal order of recycling stations based on the predicted fill levels and location
- Visualization of the optimal route via a web app
Our Result 🤗
This is how our application can be used:
- The user enters the web app via the browser and sees the location of all glass containers that are equipped with sensors.
- On the left side the user can set values that steer the calculation of the path finding algorithm and the prediction:
Leeren ab Füllstand: Threshold that defines the level (in percentage) of the containers that should be emptied. Containers with a lower level of glass contained are being ignore by the path finding algorithm.Dauer der Tour: Number of working hours that the resulting path should occupy (0-8).Glasarten: Which types of glass (white, brown, green) should be considered in the resulting path.
- After clicking
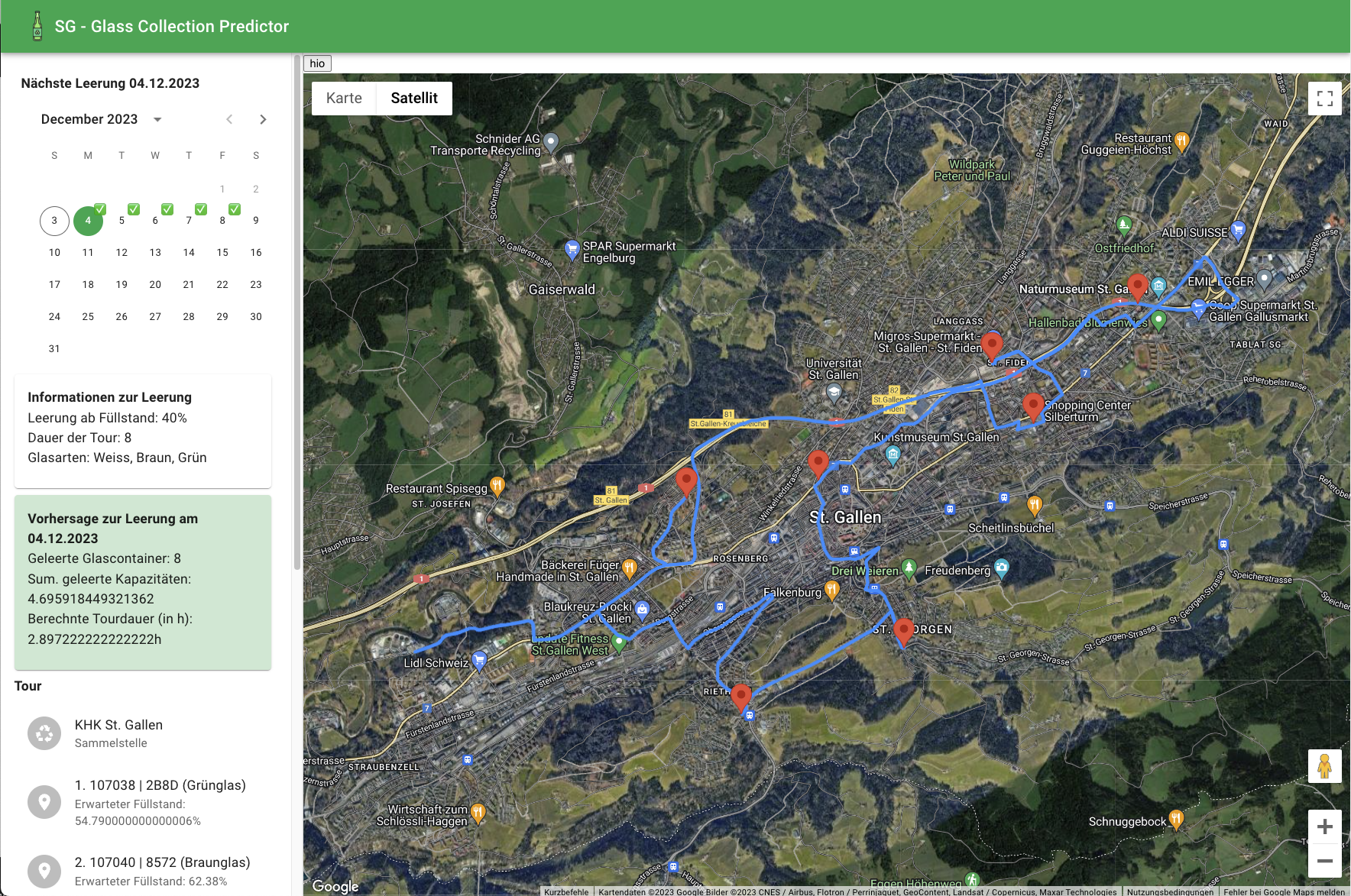
Predict, the path finding algorithm is called via a REST API that works in the background: a) The (driving) distances between the containers are calculated in a preliminary step upon startup of the REST API using Google Maps API. The distances are then saved in a file and loaded whenever needed. b) The costs are being calculated as a mixture of a greedy algorithm and a nearest neighbor algorithm. The distances between containers (nearest neighbor) are weighted by the level they are filled (greedy). c) The algorithm then starts at station0 which is fixed at the "Kehrrichtheizkraftwerk St. Gallen" and then takes on the path that has the smallest cost. d) When the most containers of a path are found, we implemented a refining step. In this step we aim to minimize the driving time by reorganizing the order of the containers in the path. - The calculated path is being displayed to the user with all the necessary infos.
- A selection for a date in the next 5 days to show the route for
- Query information of the beforehand input
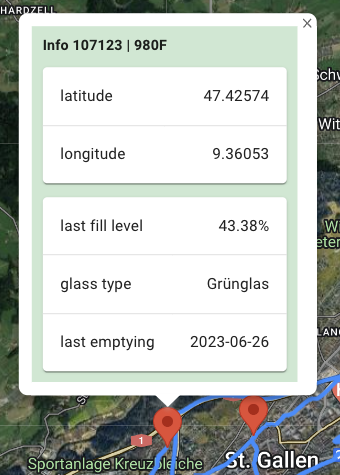
- The locations of the tour with the expected fill level of each container
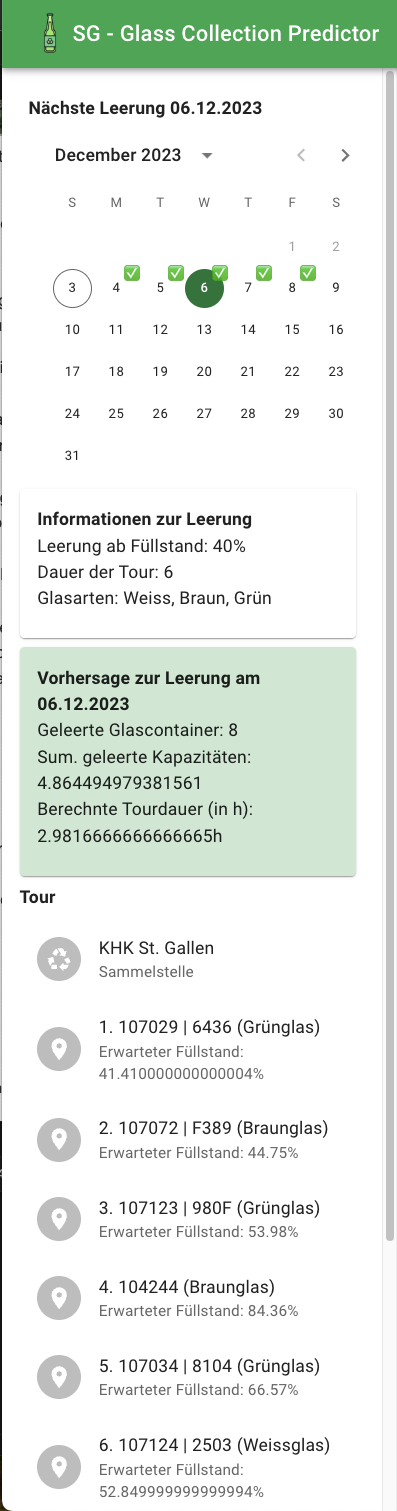
- Location of the container
- Fill Level of of the container
- Glass type of the container
- The overall route of the path
Details
Prediction for 5 days into the future
The model is trained in sequences of 5 days to predict the 6. day. Therefore, the last 5 days of data are being considered in order to calculate the predicted value for tomorrow. In order to calculate the predictions for the day after tomorrow, the previous preidiction of tomorrow is being used in a feedback loop.
#### Path Refinement As from our rough tests, the path refinement results in a reduced driving time of approximately 5-10 minutes per path.
Path Constraint
In order to make it as realistic as possible, we have defined two constraints for the path:
- The path should be calculated such that it fits into 1 working day (8h, adjustable via UI)
- The fillment level of a trough should not be exceeded (currently set to 10 containers = 1 fillment of a trough, also it is not yet distinguished between volume per glass type)
We then start at station0 (Heizkraftwerk St. Gallen) and we continuously add containers until eiher the time is excceeded (inclusive time to get back to station0) or the trough is full. The needed time is calculated by summing up the driving times and the time per emptying (fixed at 15 Minutes per container - some extra time included for gradual delays) per container.
Currently, we don't consider emptying nearby containers of other glass types which are below the set threshold but in reality, this would be a reasonable extension to the application.
Future Ideas ✨
Ideas that can be explored if there is time:
- [ ] Host on a server
- [ ] Improve the model by adding more influencing parameters such as weekday, season or fill levels of nearby ALU sensors
- [ ] Edge case handling
- [ ] Torough testing
- [ ] Vary the number of inputs, the timeranges, the number of outputs...
- [ ] Add sensor noise threshold
- [ ] Test if training on single sensors is better
Setup
Create a conda environment with conda create --name <env> --file requirements.txt. We recommend using python version 3.9.
Create a Google Maps API key and save it for later steps (you can easily find the documentation online).
Run the bash script download-data.sh. This will download the data to the data folder. Afterwards run preprocessing.py directly which will create a single csv file from all the 3 datasets.
##### Alternative Setup: Download the files below into the data folder:
- Füllstandsensoren Glassammelstellen (Weissglas)
- Füllstandsensoren Glassammelstellen (Grünglas)
- Füllstandsensoren Glassammelstellen (Braunglas)
Train the model
To train the model, the datasets must be available and merged (as done in the Setup step). The file must be available under data/days_merged.csv. Afterwards, you can execute main.py in the project root which will train the model and save a snapshot to the trained-models/ folder.
API
The Google Maps API key must be saved under as MAPS_KEY=<key> in a .env file in the project root.
In order to use the model, the datasets must be available and merged (as done in the Setup step). Also, the model must be trained. Afterwards, the command flask --app lib/api run can be executed from the project root.
UI
The Google Maps API key must be saved in a second location as REACT_APP_GOOGLE_MAPS_API_KEY=<key> in a .env file in the predictor-app/ folder.
The UI is located in the predictor-app/ folder. First run npm install in the given folder, the start it using npm run start.
Sitios - Informationen vereinfachen
openDataHack2023SG
opendatahackSitios
openDataHack2023SG
Team Sensors & Co.
Durch Datenanalysen: Auffüll- & Zuwachsrate je Glasart, Leerungszeitpunkte, Sensorzustände. Für optimierte Tourenplanung & Prognosen.
In this document we analysed the sensors of every glass type (white glass, green glas, brown glas) according to their quality (good quality -- green, middle / medium quality -- yellow, bad quality -- red, broken sensors -- lilac). This is a precise overview and summary of what can be found in the individual codes of the corresponding glass types (Braunglas_Sensors_2023.ipynb, Weissglas_Sensors_2023.ipynb, grün_broken.ipynb, grün_broken_now.ipynb) that we uploaded on GitHub:
https://1drv.ms/w/s!Amn00a3koCjPs1LUrthGmTSpEmMk?e=0M7rxQ
Auswertung des Füllverhaltens von Glassammelstellen in St. Gallen im Rahmen des Open Data Hack St.Gallen
Challenge Owner
Roman Breda & Marc Maurhofer, Entsorgung St.Gallen
Ausgangslage
Entsorgung St.Gallen ist die Fachstelle der Stadt St.Gallen für die umweltgerechte Entsorgung fester und flüssiger Abfälle. Wir sind hilfsbereite Ansprechpartner für Private, Gewerbe, Medien, Schulen und andere Interessierte. Zertifizierungen für Qualität, Umwelt, Sicherheit und Gesundheit stellen sicher, dass wir natürliche Ressourcen schonen und die Risiken unserer Arbeit beherrschen. Entsorgung St.Gallen wird durch kostenbasierte Gebühren und Beiträge finanziert.
Um Wertstoffe in den Kreislauf zurückzuführen betreibt Entsorgung St.Gallen stadtweit ca. 30 Sammelstellen für Glas. Gemäss Entsorgungsstatistik werden jährlich ca. 2’500 Tonnen Glas gesammelt. An jeder Sammelstelle gibt es Container für Grün-, Weiss- und Braunglas, die mit einem Füllstandsensor ausgerüstet sind und die Daten als Open Data zur Verfügung gestellt Die Anzahl Container pro Farbe variiert.
Entsorgung St.Gallen verfügt über ein Sammelfahrzeug mit Mulde, in welcher das Glas farbgetrennt gesammelt werden kann. Die Container werden nach Erfahrungswerten geleert, immer mit der Zielsetzung, dass am Wochenende keine Überfüllung und daraus folgend Reklamationen der Bevölkerung erfolgt.
Eine technische Lösung im Sammelfahrzeug mit z.B. Online-Anzeige der Füllstände wurde bisher nicht umgesetzt, auch aufgrund der langjährigen Erfahrung des derzeitigen Fahrers. Für die Zukunft wird jedoch eine technische Lösung angestrebt. Eine Tourenplanungssoftware für Kehricht und Grüngut ist vorhanden und könnte für die Glassammlung erweitert werden.
Aufgabenstellung
Wie können wir anhand der Sensordaten das Füllverhalten der Glas-Sammelstellen ermitteln, um die Tourenplanung bei der Glassammlung unterstützen zu können.
Es soll geprüft werden, inwiefern es Unterschiede zwischen den Glasfarben gibt und ob das Verhalten an allen Sammelstellen ähnlich ist. Folgende Fragestellungen könnten dabei helfen:
-
Gibt es einen Zusammenhang zwischen Merkmalen wie Demografie, Bevölkerungs-dichte, etc. und dem Füllverhalten? -
Ist das Füllverhalten über das ganze Jahr ähnlich und über mehrere Jahre vergleichbar? -
Können die Sammelstellen bspw. nach oben erwähnten Merkmalen kategorisiert werden?
Anforderungen
Die Daten müssen überprüft und mögliche Messfehler berücksichtigt werden. Zu beachten ist auch, dass die Sensoren durch die Kegelbildung bei der Befüllung der Container falsche Füllstände anzeigen können.
Die Füllstandssensoren wurden seit Mai 2022 nicht mehr gewartet, daher können einige Sensoren defekt oder die Batterien leer sein.
Ziele & Erwartungen
Entsorgung St.Gallen wünscht sich einen Algorithmus, mit welchem die Sammlung optimiert werden kann. Die Optimierung würde in einem weiteren Schritt vorangetrieben.
Ressourcen
-Bevölkerungsstatistiken über STADA2 abrufbar
Aufbau Repository
Team Wololoo
Flasche leer Wololoo
Getting started
To make it easy for you to get started with GitLab, here's a list of recommended next steps.
Already a pro? Just edit this README.md and make it your own. Want to make it easy? Use the template at the bottom!
Add your files
- [ ] Create or upload files
- [ ] Add files using the command line or push an existing Git repository with the following command:
cd existing_repo
git remote add origin https://gitlab.ost.ch/hannes.scherrer/flasche-leer-wololoo.git
git branch -M main
git push -uf origin main
Integrate with your tools
Collaborate with your team
- [ ] Invite team members and collaborators
- [ ] Create a new merge request
- [ ] Automatically close issues from merge requests
- [ ] Enable merge request approvals
- [ ] Set auto-merge
Test and Deploy
Use the built-in continuous integration in GitLab.
- [ ] Get started with GitLab CI/CD
- [ ] Analyze your code for known vulnerabilities with Static Application Security Testing(SAST)
- [ ] Deploy to Kubernetes, Amazon EC2, or Amazon ECS using Auto Deploy
- [ ] Use pull-based deployments for improved Kubernetes management
- [ ] Set up protected environments
Editing this README
When you're ready to make this README your own, just edit this file and use the handy template below (or feel free to structure it however you want - this is just a starting point!). Thank you to makeareadme.com for this template.
Suggestions for a good README
Every project is different, so consider which of these sections apply to yours. The sections used in the template are suggestions for most open source projects. Also keep in mind that while a README can be too long and detailed, too long is better than too short. If you think your README is too long, consider utilizing another form of documentation rather than cutting out information.
Name
Choose a self-explaining name for your project.
Description
Let people know what your project can do specifically. Provide context and add a link to any reference visitors might be unfamiliar with. A list of Features or a Background subsection can also be added here. If there are alternatives to your project, this is a good place to list differentiating factors.
Badges
On some READMEs, you may see small images that convey metadata, such as whether or not all the tests are passing for the project. You can use Shields to add some to your README. Many services also have instructions for adding a badge.
Visuals
Depending on what you are making, it can be a good idea to include screenshots or even a video (you'll frequently see GIFs rather than actual videos). Tools like ttygif can help, but check out Asciinema for a more sophisticated method.
Installation
Within a particular ecosystem, there may be a common way of installing things, such as using Yarn, NuGet, or Homebrew. However, consider the possibility that whoever is reading your README is a novice and would like more guidance. Listing specific steps helps remove ambiguity and gets people to using your project as quickly as possible. If it only runs in a specific context like a particular programming language version or operating system or has dependencies that have to be installed manually, also add a Requirements subsection.
Usage
Use examples liberally, and show the expected output if you can. It's helpful to have inline the smallest example of usage that you can demonstrate, while providing links to more sophisticated examples if they are too long to reasonably include in the README.
Support
Tell people where they can go to for help. It can be any combination of an issue tracker, a chat room, an email address, etc.
Roadmap
If you have ideas for releases in the future, it is a good idea to list them in the README.
Contributing
State if you are open to contributions and what your requirements are for accepting them.
For people who want to make changes to your project, it's helpful to have some documentation on how to get started. Perhaps there is a script that they should run or some environment variables that they need to set. Make these steps explicit. These instructions could also be useful to your future self.
You can also document commands to lint the code or run tests. These steps help to ensure high code quality and reduce the likelihood that the changes inadvertently break something. Having instructions for running tests is especially helpful if it requires external setup, such as starting a Selenium server for testing in a browser.
Authors and acknowledgment
Show your appreciation to those who have contributed to the project.
License
For open source projects, say how it is licensed.
Project status
If you have run out of energy or time for your project, put a note at the top of the README saying that development has slowed down or stopped completely. Someone may choose to fork your project or volunteer to step in as a maintainer or owner, allowing your project to keep going. You can also make an explicit request for maintainers.
Team?
Readme -> Cantbeard/opendatasg_cntft (github.com),
Funktionierender präsentationslink -> 2023-12-03 07-10-51 on Vimeo
glassplots.py
Generiert plots aus "entsorgungsstatistik-stadt-stgallen.xlsx" (permonth, totalplot)
greenglassplot.ipynb
Jupyter notebook um überblick über grünglassdaten zu gewinnen (x = sekunden seit 2020-01-01, y = distanz)
glassdata.py
Liest opendata excelfile ein (z.B. fuellstandsensoren-glassammelstellen-braunglas.xlsx) und erstellt daraus defects_fuellstandsensoren-glassammelstellen-_______glas.txt und result_fuellstandsensoren-glassammelstellen-_______glas.xlsx
defects_fuellstandsensoren-glassammelstellen-_______glas.txt
Liste der Sensor IDs, die in den letzten 2 monaten keine daten gesendet haben.
result_fuellstandsensoren-glassammelstellen-_______glas.xlsx
Tabelle der device_id, deren Geo_Point_2D koordinaten und durchschnittlichefüllungsgeschwindigkeit seit messbeginn
Visualisierung von umfassenden Informationen
Ein Beispiel zur Visualisierung von Daten über Zugangsmöglichkeiten aus der Ginto Guide App
parlerStadtparlament
Open Data Hack Challenge No. 5: Welche Themen beschäftigen das Stadtparlament St.Gallen wie stark?
Video Alternativer Link auf [Google Drive](https://drive.google.com/drive/folders/1RKf1eUuCuI7YBX5QFhoou2vY0h7xMyzC?usp=drive_link](Google Drive))
Open Data Hackathon Challenge parlerment
Open Data Hack St.Gallen 2023
README Verzeichnis
Ausgangslage
Auf der Open-Data-Plattform der Stadt St.Gallen liegt ein Datensatz mit den Geschäften aus dem St.Galler Stadtparlament. Darin aufgeführt sind etwa der Titel des einzelnen Vorstosses, welche Poltiker:in ihn eingereicht hat, und welche Partei dadurch dahinterstand.
Über den Datensatz sind zu jedem Geschäft die dazugehörigen Dokumente downloadbar. Bei Vorstössen etwa der jeweilige Vorstoss und die Antwort des Stadtrates darauf. Die Dokumente liegen als PDFs in einem Zip-Ordner vor.
An einem früheren Hackathon haben Studierende der Fachhochschule OST einen Code geschrieben, der den Volltext jedes Dokuments ausliest und dem jeweiligen Geschäft hinzufügt. Es wurde ausserdem versucht, jedem Geschäft ein Thema zuzuordnen, was aber nicht verlässlich gelang.
Um das volle Potenzial des Datensatzes ausreizen zu können, ist das jedoch nötig. Gerade vor Wahlen könnte der Datensatz so Einsichten liefern, für welche Themen sich welche Parteien wie stark einsetzen.
Aus diese Grund wurde diese Aufgabe als Challenge am Open Data Hack St.Gallen eingereicht.
Datenquellen
-
Ein Datensatz auf der Open-Data-Plattform der Stadt St.Gallen: "Traktandierte Geschäfte in Sitzungen des Stadtparlaments St.Gallen (RIS – Ratsinformationssystem)". Der Datensatz enthält auch Links zu den Sitzungsprotokollen des Stadtparlaments.
-
Eine Kaggle-Competition (kaggle.com/competitions/male-stgallen-recommender) mit einer detaillierten Problembeschreibung.
-
Code von Studierenden (bei Beat Tödtli beziehbar). Der Code ermittelt eine Vorhersage des Themas aufgrund der Titel der Geschäfte und den Kategorien aus dem Aktenplan. Das Machine Learning Modell muss jedoch weiterentwickelt werden, um die Verlässlichkeit bedeutend zu erhöhen.
Ziel
Für jedes einzelne Geschäft sollen dem Datensatz dessen wichtigsten Themen hinzugefügt werden. So sollen Auswertungen möglich werden wie zum Beispiel:
- Wie oft hat sich das Stadtparlament mit dem Thema X beschäftigt?
- Welche Themen waren im Jahr Y, im Zeitraum Z besonders wichtig?
- Wie hat sich die Themenkonjunktur über die Jahre/Jahrzehnte entwickelt?
- Welche Parteien/Fraktionen widmeten sich welchen Themen? Und wie hat sich das verändert?
- Interessiert sich die SP vor allem für schulische Themen und die FDP vor allem für Finanzthemen?
- Worüber wird im Stadtparlament kaum je diskutiert?
- Sind klimapolitische Themen seit Fukushima stärker auf der Agenda als davor?
Der Code, um solche Auswertungen möglich zu machen, soll in einer Form vorliegen, dass er weiterentwickelt werden kann. Marlen Hämmerli, Datenjournalistin beim "St.Galler Tagblatt" und Challengeownerin möchte mit dem Code weiterarbeiten und ihn auch weiter entwickeln.
In einem zweiten Schritt stand es dem Team offen, ein Tool/Dashboard zu bauen. Dadurch sollte es der breiten Öffentlichkeit - und damit der Wählerschaft - möglich werden, eigene Analysen vorzunehmen.
Vorgehen
- Llama wurden Themen vorgegeben und die KI angewiesen, jedem Geschäft das passende zuzuordnen. So wurde der Datensatz mit Hilfe bekannter Tools (pandas) erweitert.
- Die Volltexte wurden nach Quartiernamen durchsucht, um so festzustellen, welche Geschäfte welchem Quartier zugeordnet werden können. (Oder nicht.) Auf diese Art wurde der Datensatz erweitert.
- Mit ChatGPT-4 wurden ebenfalls Themen abgefragt, aber auch Prompts mitgegeben wie z.B. "Wie links oder rechts ist Vorstoss X?"
- ChatGPT wurde mit den Datensätzen trainiert mit dem Ziel, die KI in einem Dashboard einzubetten.
- Mit Power BI wurden Visualisierungen erstellt.
- Ein Dashboard wurde erstellt, in das die genannten Ergebnisse einflossen.
Limitationen
Bei der Auswertung wurde nur auf die Vorstösse konzentriert. Jedem Vorstoss sind jedoch zwei Dokumente beigelegt. Neben jenem vom Parlament, auch jenes vom Stadtrat. Diese konnten nicht aus dem Datensatz gefiltert werden, flossen also in die Auswertung ein.
Prozess Architektur

Mögliche Weiterentwicklungen
Die Integration von ChatGPT.
Team
- Marlen (marlen.haemmerli@tagblatt.ch)
- Raquel (raquel.kehl@ost.ch)
- Beat (beat.toedtli@ost.ch)
- Orhan (orhan.saeedi@bs.ch)
- Till
- Tobias (tobidex@gmx.de)
- Simon